本节通过一个简单的逻辑回归实例来熟悉Tensorflow的开发流程,整个流程可以总结为五个步骤:准备数据、搭建模型、迭代训练、评价分析、使用模型。
准备数据
一般地,根据具体的任务,我们会得到一定的标注数据,我们通常会把数据拆分为训练集、验证集和测试集,训练集用来训练模型,验证集用来调参,测试集用来评估性能。这里,我们为了操作的简单性,自行生成一组数据集,这是关于$x$和$y$的简单线性关系,其中$x$和$y$的对应关系为 $y \approx 2x$
1 | import numpy as np |
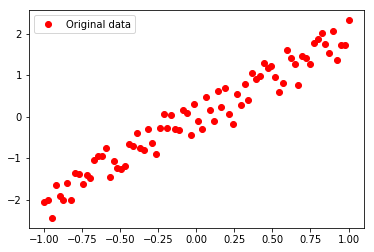
从训练集的可视化图像中可以看出,我们刻意加入的噪声使得部分数据点随机地分布在了$y=2x$的直线两侧,而我们的目标正是通过数据这种近似的分布拟合出$y=2x$的线性关系。
搭建模型
搭建Tensorflow的模型分为两步:正向搭建和反向搭建。正向搭建是自底向上逐层架起神经网络的过程,反向搭建是模型的优化过程。由于我们的任务本身很简单,在这里只需要搭建一个包含单一神经元的最简单神经网络就可以实现对$y \approx 2x$的线性关系的拟合。
1 | import tensorflow as tf |
尽管上面的代码很简单,但足以说明一个完整的Tensorflow建模过程的主要步骤:
- 为输入数据和目标值(输出)定义占位符
- 将模型中的参数定义为变量(在训练过程中会不断地变更)
- 定义数据与参数的运算关系(包括神经网络的非线性计算)
- 定义损失函数,它是真实输出值与模型输出值的评价函数
- 选择优化器,用来最小化损失函数
其实,我们可以把占位符、变量、算子都当做是节点,通过运算关系将这些节点串联起来,这种串联具有一定的流动方向,仿佛是一张有向图,所谓的搭建模型其实就是画出数据的运算流程图。
迭代训练
前面构建好的模型如同搭建起了一套自来水的管道(静态的),训练的时候我们需要启动一个会话(动态的),在会话中分批次地把数据注入管道,并从管道网络中指定的节点处取得流出的数据。这个对于训练过程流出的数据就是损失loss,通常我们会把每次取到的这个值输出,以便观察训练过程是否朝着正确的方向(不断减小损失)不断迭代。
1 | #初始化所有变量 |
Epoch: 1 cost= 0.9330804 W= [0.5178577] b= [0.46305528]
Epoch: 3 cost= 0.16383864 W= [1.5301253] b= [0.19926287]
Epoch: 5 cost= 0.095674135 W= [1.8054278] b= [0.09571465]
Epoch: 7 cost= 0.08990188 W= [1.8768404] b= [0.06834576]
Epoch: 9 cost= 0.08921726 W= [1.8953096] b= [0.06125886]
Epoch: 11 cost= 0.08909434 W= [1.900085] b= [0.05942642]
Epoch: 13 cost= 0.08906618 W= [1.9013196] b= [0.05895258]
Epoch: 15 cost= 0.08905912 W= [1.9016391] b= [0.05883]
Epoch: 17 cost= 0.08905732 W= [1.901722] b= [0.05879813]
Epoch: 19 cost= 0.08905686 W= [1.901743] b= [0.0587901]
Finished!
cost= 0.0890568 W= [1.9017464] b= [0.05878884]
通过上面的代码可以看到,模型的迭代训练可以总结为如下几个步骤:
- 初始化所有的变量( init = tf.global_variables_initializer() )
- 启动一个会话( with tf.Session() as sess )
- 按轮次迭代( for epoch in training_epochs )
- 按数据批量更新训练,训练就是执行optimizer( sess.run(optimizer, feed_dict={X:x_batch, Y:y_batch}) )
- 定时输出训练参数或保存之以便绘图分析( 训练参数主要关注loss的变化、模型参数的变化、评测指标的变化等 )
- 训练完成后保存模型( saver.save(sess, “./model.ckpt”) )
为了能更形象地去理解Tensorflow的运行机制,我们可以把构建的网络当做一个水管管道布局,输入的数据就是水,而会话就是一台抽水机,刚刚构建好的管道是空的,需要我们把水在源头通过feed_dict注入到管道中,而无论我们在管道的哪一个节点获取水(包括在源头注入),都需要运行这台抽水机sess.run(node)。
评价分析
可视化地展示训练过程中训练、评测参数或模型参数的变化趋势,有利于我们分析训练过程中何时模型趋于稳定,以及是否出现了过拟合问题。
1 | #图形显示 |
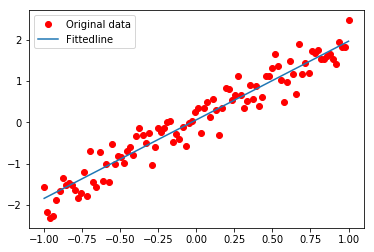
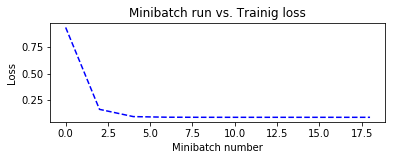
复用模型
复用模型的前提是我们在训练过程结束时已经使用saver对模型进行了保存,复用时只需要restore模型就可以了。restore的过程相当于重新把那套自来水管道复原,同时把管道上的参数(相当于水流控制开关)也加载恢复了,使用模型时再次注入水流(数据)就可以了,不同于训练过程,此时应该获取水流的节点是最终输出的那个节点(不是loss所在的节点)。
1 | with tf.Session() as new_sess: |
INFO:tensorflow:Restoring parameters from ./model.ckpt
x=0.2, z= [0.4391381]